A short and single line in R produces a complex figure with various information: the generic ‘plot’ yields a plot as seen in the left panel of Figure 4 or can make a graphical presentation of downscaled results that both shows the numbers as well as their quality. How is that possible? The trick is to define different data object types, known as ‘classes’ in R and define a specific data reference syntax (DRS) or common information model (CIM) that includes the meta-data in the working computer memory as well as in files stored on discs. This is all done automatically on-the-fly behind the scene, so that the user does not have to worry about these matters (it is of course possible to change the meta-data to e.g. correct for potential errors).
The command library(‘esd’) must be given at any new open R session. The R-package can be installed directly from Github or Figshare for Mac/Linux and Windows.
Retrieving data: I/O
There are different types of data that can be handled by the ‘esd’ tool: station data, gridded data, and (storm) trajectories. Station data contain meteorological observations recorded at weather (or hydrological) stations, while gridded data can comprise various analyses (e.g. E-OBS gridded version of the European and Climate Assessment data set), reanalyses (e.g. NCEP, ERA, …) or global/regional climate model results (e.g. CMIP3/5 experiment). Trajectories are
mainly used for analysis of storm tracks (e.g. IMILAST). There are two main methods for retrieving data in the ‘esd’ tool: ‘station’ and ‘retrieve’.
It is also possible to read data using the R-built in functions and convert it to esd data format. This requires more effort from the user using the ‘esd’ pre-defined functions as.station, as.field), and as.trajectory. The package comes with a set of sample data mainly included for demonstration purposes,
testing, or troubleshooting. For gridded data, these are filtered data (mainly for reducing the size of the data objects) and should not be used as predictors in the actual analysis. For instance, air temperature reanalysis data are stored as a set of 20 empirical orthogonal functions (EOFs) with global coverage, which are then transformed to a field object upon a retrieval. However, the sample station data can be used without restrictions and corresponds to observed values at a specific location (e.g. data(Oslo) or nacd=station(src='nacd')).
Function retrieve()
The ‘retrieve’ is designed to read data from NetCDF files following the standard Climate and Forecast (‘CF’) conventions and ordered on a longitude-latitude grid. The latter could be regular or irregular grid (e.g. the output of the Weather Research and Forecasting model (WRF) or any outputs on a rotated grid from RCMs). The function ‘retrieve’ also performs quick checks of the data itself to verify that the meta data and data are consistent. For instance, in case the frequency of the data is missing, retrieve() will try to detect the frequency automatically form the data itself. The function retrieve returns two types of objects depending on the type of the spatial grid. For instance, data stored on a regular grid is returned as field objects including attributes containing meta data, and data stored on irregular grid - such as rotated longitude-latitude grids - are returned as a station objects.
The function retrieve() has also been adapted to read global climate data from the CMIP3/5 experiments, most of the global reanalysis such as those provided by the European Centre for Medium-Range Weather Forecasts (ECMWF) known as ERA-40 and ERA-INTERIM, the National Center for Environmental Prediction (NOAA) known as NCEP/NCAR reanalysis, the Japan Meteorological Agency (Japanese Reanalysis JRA-25,55), and the NASA GSFC Global Modeling and Assimilation Office (GMAO) known as MERRA reanalysis. A full overview of all available reanalysis can be found here.
As for now, retrieve(), does not display a list of missing attributes that are mandatory for further post-processing of the data. The user must add the missing attributes manually. The strength of retrieve() is that it can read and return formatted objects with common attributes for post-processing, visualising and making outputs comparable (e.g. re-gridding the field objects into the same grid resolution). Basically, all reanalysis, general circulation models (GCMs), and regional climate models (RCMs) can be read using the ‘esd’ tool and further combined into one object, or analysed, albeit with some limitations due to the size of
the returned object.
Function station()
The package ‘esd’ includes the function ‘station’ for obtaining historical climate data by querying various web portals, for instance, the MET Norway archive (KDVH) provided by the Norwegian Meteorological Institute through eKlima website. Data from MET climate web service ‘eKlima’ needs to be adapted manually, the Global Historical Climate Network (GHCN, (Peterson and Vose,1997)) provided by the American National Climatic Data Center at , and the European Climate Assessment and Dataset (ECA&D), (Klein Tank et al., 2002)) made available by the Royal Netherlands Meteorological Institute (KNMI). Some of the data that is; however, this function only works within the firewall included in the package has been pre-formatted within the ‘clim.pact’ package and adapted to meet the new ‘esd’ data format requirements.
Quick search - Function select.station()
The sample data includes also a meta-data object stationmeta that can be loaded directly and contains meta data such as name of the location loc and its standard ientification number stid, geographical coordinates such as longitude lon, latitude lat, and altitude alt, country name country, parameter name param of recorded weather variables (e.g. temperature and precipitation), data source src or provider for thousands of stations all over the world (Figures 1 and 2).
These meta-data have been imported from existing meta data from the different data source providers. It has to be noted also that most of the available stations are managed by the World Meteorological Organisation (WMO) and made available by the American National Climate Data Centre (NCDC) for scientific research only. The meta data has been merged from the different sources mentioned earlier. Also, other additional data sources can be easily included into the package.
Figure 1: Map of available weather stations recording temperature that are included in the meta-data of the ‘esd’ package.
Figure 2: Map of available weather stations recording precipitation that are included in the meta-data of the ‘esd’ package.
There are two ways of obtaining station data using station() method. The first option, which we recommend, is to select a subset of stations from the meta data using the function select.station() from a set of criteria. Among these criteria, the minimum length of the recorded data (‘nmin’) can be specified to get, for instance, a subset of stations recording for at least a minimum number of (e.g. 100) years of data (e.g. select.station(nmin=100)). Thus, a subsample of the meta data is returned and can be checked for duplications of stations from the various sources. Afterwards, users can start downloading the data for the selected stations. It has to be mentioned that the downloading process for the GHCN and ECA&D is different as the data is stored differently. For the GHCN data sets, each station is stored separately and a direct retrieval can be made. We highly recommend that users perform a prior selection of stations for the GHCN data sets before starting the downloading process. For the ECA&D data sets on the other hand, all stations are downloaded and stored locally as zip files at first call, after which data is extracted for the selection of stations. Other data sets, such as the NACD (Frich et al., 1996), NARP (Førland ), and Nordklim (Tuomenvirta et al., 2001) are stored entirely in ‘esd’ (only holds monthly values of a limited set).
The ‘station’ method can retrieve station data from a range of different sources, many over the web (GHCN and ECA&D). Example 2.1 demonstrates how to select, retrieve and plot temperature observations from a single station. The ‘esd’ toolbox holds meta-data for various data sources, which makes it quick and easy to search for weather data recorded at stations according to the parameter, the geographical location (region, country, and coordinates (single or a range of longitude and latitude values) and altitude, and time interval.
Figure 3: Map showing available stations across India from the GHCN-D dataset and b) a plot of the annual maximum temperature recorded at New Delhi weather station (blue point) including linear trend line.
Data structures
Most data objects handled by ‘esd’ are typically time series, and hence based on the zoo class. The zoo class extends the tseries class from regular to irregular time series. In the ‘esd’ tool, additional categories or classes have been defined dealing with temporal resolution distinguishing daily (‘day’), monthly (month), seasonal (season), and annual (annual) data (as temporal classes) and spatial resolution distinguishing location (station) and field
(field) classes.
Data on sub-daily scales may be represented in the ‘day’ class but the ‘esd’ tool has not been tested yet for this time scale. The way R handles different classes and objects can sometimes be confusing. The first element in a list of different classes is used to identify the appropriate method to be used for that specific object. For instance, if a data object belongs to the classes (‘field’,‘zoo’), then, appropriate methods for ‘field’ objects are used rather than those for
the ’zoo’ objects. Different types of data objects are processed and handled differently, and the way ‘esd’ keeps track of the different types is through the so-called ‘S3-method’ and classes. The ‘esd’ tool follows the same R programming functionalities and uses the first element of the class of an object to define the appropriate method to be used. The built-in R functions class and inherits are used to check whether an object inherits from any of the classes specified in the ‘esd’ package. Example 2.2 shows some of the classes used in ‘esd’.
The different data objects come bundled with relevant meta-data, stored as data attributes. These are shown using the str() (structure) function, as displayed in Example 2.3 for a station object.
The various attributes have different functions, e.g. for handling the data, traceability, identification, and visualisation. The idea is that they are based on a standard terminology for which the terms are commonly agreed on and follow standard definitions. A common core set of attributes will make it easier to share data and methods. The attribute history contains the call(s) (call), time stamp(s), and session info that have been used to create and process the data itself.
Function summary()
The S3 method ‘summary’ has been extended to the classes defined in ‘esd’ in order to provide more tailor-made information. Example 2.4 shows summary statistics for each calendar month of a daily station object.
Table 1: Data objects in ‘esd’ are determined by a set of classes, listed in this table. This may be extended in the future to include radiosonde and radar data objects.
| ‘station’ | Class defining station objects. Can be single or multiple stations with daily, monthly, seasonal or annual temporal resolution. |
| ‘spell’ | Looks similar to the station class, but the events are irregularly spaced and contains both duration of wet/hot as dry/cold spells. The distinction also enables ‘esd’ to apply different plotting and analysis methods than those for regular stations. |
| ‘field’ | Currently represents time series of 2D variables, but may in principle contain any number of spatial dimensions. |
| ‘eof’ | Class defining an EOF describing the spatial patterns (EOFs), the temporal variations (PCs), and the eigenvalues. |
| ‘pca’ | Class defining a PCA is similar to the eof class, but allows for irregular grid of stations. |
| ‘cca’ | Class that defines the results of a CCA, containing a pair of patterns and the canonical correlations. |
| ‘ds’ | Class for DS results. |
| ‘dsensemble’ | Class for downscaled ensembles. |
| ‘diagnose’ | Class for diagnostic results. |
| ‘trajectory’ | Class for trajectories. |
| ‘xval’ | Class for cross-validation. |
| ‘xsection’ | Class for cross-sections (Hovmuller diagrams). |
| ‘mvr’ | Class for multivariate regression (MVR) objects, which hold the matrices that maps one data set onto the data space of another. |
Data visualisation
The main data visualisation is provided through plot and map methods, but there are other more specific methods for producing additional graphs.
Function plot()
The plot() method in ‘esd’ extends the S3 plot methods from package graphics to new esd classes (Table 1). plot(x) and plot.station(x) are equivalent if x is an object of class station. Various plotting outputs are generated depending on the class of the objects used as inputs. For instance, the plot.station(x) function produces a figure based on the default ‘graphics’ and ‘zoo’ plots but adapted for the station object (Figure 4a). For some classes, plot can produce several or a combination of plots giving more description of the output. The argument ’plot.type’ is also used to distinguish between single or multiple plots in one window. The plot function also inherits all graphical parameters from ‘par’ with additional parameters used by esd. An example of the function plot applied to a station object is shown in Example 2.5 and Figure 4a. Although the plot itself gets more complicated for EOFs, the syntax remains as simple as for the station object (Example 2.6, Figure 5).
Figure 4:
 Figure 5: An example of a plot results for an EOF object.
Figure 5: An example of a plot results for an EOF object.
Function map()
The function ‘map’ is also an S3 built method and used to produce a map of geographical and geophysical data points and gridded data. ‘map’ can be seen as a spatial plotting method, while plot is mainly used for time series. Unlike plot, map is proper to esd and is an S3 method and do not extend the existing map function from package maps (http://CRAN.R-project.org/package=maps), which too works for the different esd objects. When applied to one single station, map plots its location (Example 2.5, Figure 4b).
Function vec()
The function vec plots vectors of a 2D flow field (Example 2.7, Figure 6).
Figure 6: The output of the example with function vec(). In this example, there are different plotting windows for the vectors and the underlying map, but this can be adjusted in the arguments of ‘vec’.
Info-graphics
One of the purposes of ‘esd’ is to easily produce visualisation and graphics to bring out new aspects of the information embedded in the data. The development of the info-graphics in this tool has also been inspired by Spiegelhalter et al. (2011), in order to distill the essence of the analysis.
The information stored in climate data can be extracted in various ways, with emphasis on different aspects, as can be seen in Example 2.8 and Figure 7. A cumugram() is shown, displaying the cumulative average value of some variable starting from the first day of the year. The results for the Oslo temperature in this example shows that 2014 has been the warmest year on record since the summer. A ‘rainbow structure’ is consistent with a gradual increase in the temperature. The second diagram, ‘wheel’, emphasises the time of the year when the most extreme events have taken place, and ‘climvar’ to the right shows how the year-to-year variance varies with season with a minimum in late summer. The ‘diagram’ method can also be used to view the data by comparing day-by-day values of the present temperature with those of the previous years. The figure shows that there have been some exceptionally mild autumn temperatures in 2014. Other functions for making info-graphics include vis.*, which make alternative graphics output displaying different information. Trends can be estimated by linear regression using the simple ‘trend’ function. An alternative trend analysis can be done using the function ‘vis.trends’ which estimates linear regressions for sliding periods of various lengths (Example 2.9, Figure 8). The results are presented visually with the strength of the trends shown as a colour scale on a grid where the x- and y-axes represent the starting point and the length of each period, respectively. Periods with statistically significant trends are marked with black outlines. The advantage of vis.trends is that it shows trends of various time scales, considering all variations of start- and end-points. The longest period is found in the upper left corner, representing the full length of the time series. The most recent period is shown in the bottom right corner. As demonstrated in Example 2.9, the strength and significance of estimated trends are sensitive to the period considered. The multiple period trend analysis is therefore a more robust alternative to single period trend fitting.
https://metno.github.io/esd/examples/#example-27-on-how-to-retrieve-wind-data-sets-and-visualise-the-results
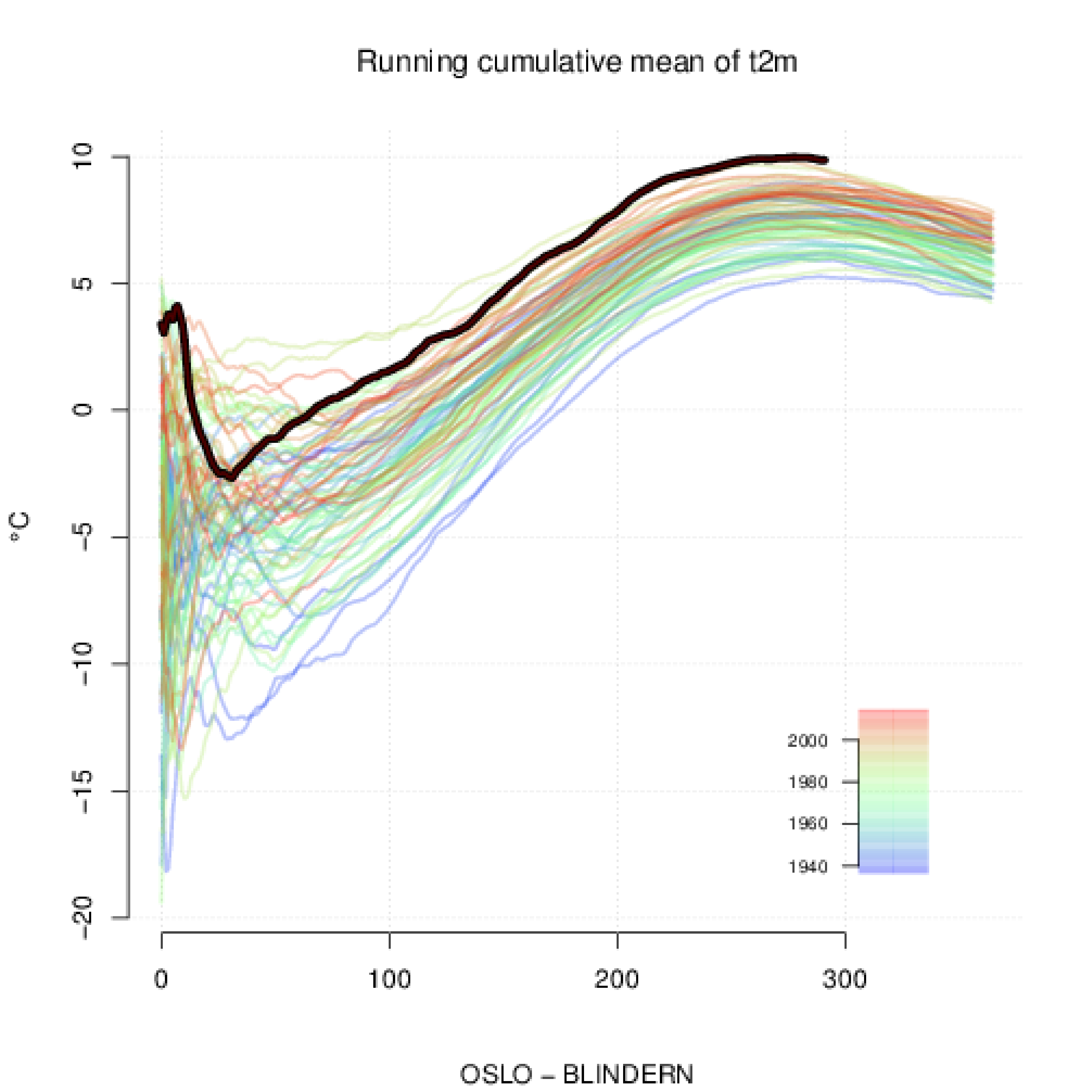
Figure 7: Examples of cumugram(), wheel(), climvar(), and diagram() plots. The cumugram shows how the mean value of some variable has evolved from the start of the year and compares this curve to previous years. The graphics produced by ‘wheel’, on the other hand, emphasises how the seasonal variations affect the variable, e.g. whether some extremes tend to be associated with a specific season. Panel c shows results produced by ‘climvar’ shows the year-to-year statistics for a variable, e.g. the standard deviation of the temperature on February 1st. The diagram method can be used in different context, and for a station object, it produces graphics that compare the day-to-day values with those of previous years.
 Figure 8: Visualising the trend in the temperature time series from Ferder for the full period (left panel) and simultaneously for different periods of various length (right panel). The trend analysis indicates a significant increase in temperature at Ferder since the 1900s, but also shows that the strength and significance of the trend is sensitive to the period considered because the increase is not monotone.
Figure 8: Visualising the trend in the temperature time series from Ferder for the full period (left panel) and simultaneously for different periods of various length (right panel). The trend analysis indicates a significant increase in temperature at Ferder since the 1900s, but also shows that the strength and significance of the trend is sensitive to the period considered because the increase is not monotone.